Python 爬虫
标签:
urllib
requests
requests
BeautifulSoup
xpath
正则表达式
cookies
selenium
scrapy
appium
MySQL
分布式
我们的口号是:让天下没有爬不到的数据!

用 urllib 采集数据
2018-04-20

用 Requests 采集数据
2018-04-29

BeautifulSoup、XPath、正则表达式 提取数据
2018-05-20
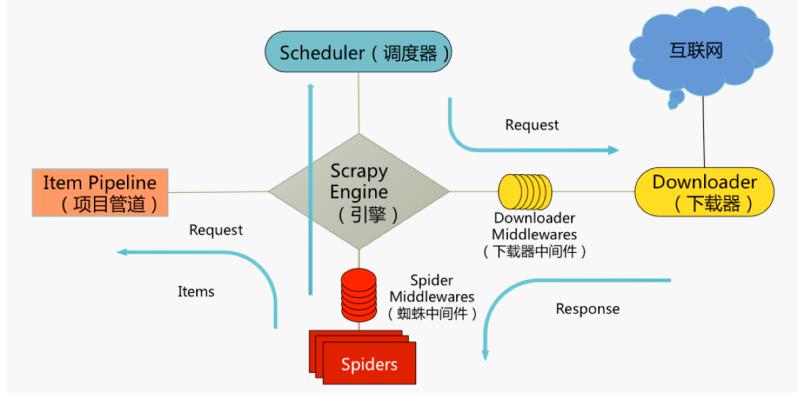
用 Scrapy 进行大规模采集
2019-04-20

用 Selenium 模拟真人操作
2018-07-20

用 Appium 进行移动端采集
2019-06-01

用 Cookies 绕过登陆采集
2018-06-15

用 Scrapy+Selenium 进行破解登录
2019-04-29
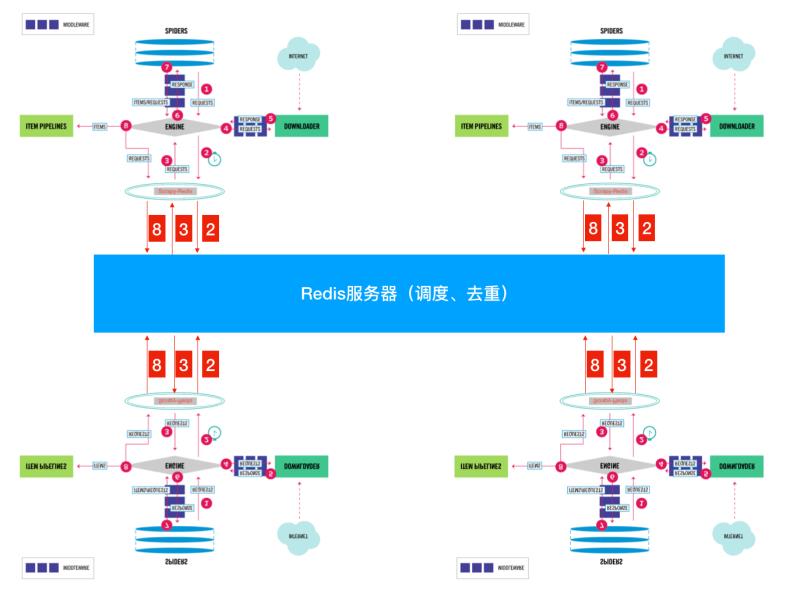
分布式采集
2019-05-01

反爬绕过
2020-02-24