【scrapy】
标签:
爬虫框架
结构化爬取
前边介绍 Rqeusts 库已经能应对大部分爬虫工作,但是它是基于页面及的爬虫库,而 Scrapy 是一个重量级的爬虫框架,它提供了一整套工具:包含对页面的爬取,爬取规则的制定,数据的提取,入库等。
Requests 和 Scrapy 比较如下:
| Requests | Scrapy |
| 页面及爬虫 | 网站及爬虫 |
| 功能库 | 框架 |
| 并发性考虑不足,性能较差 | 并发性好,性能较高 |
| 重点在于页面下载 | 重点在于爬虫结构 |
| 定制灵活 | 一般定制灵活,深度定制困难 |
| 上手十分简单 | 入门少难 |
Scrapy 架构:
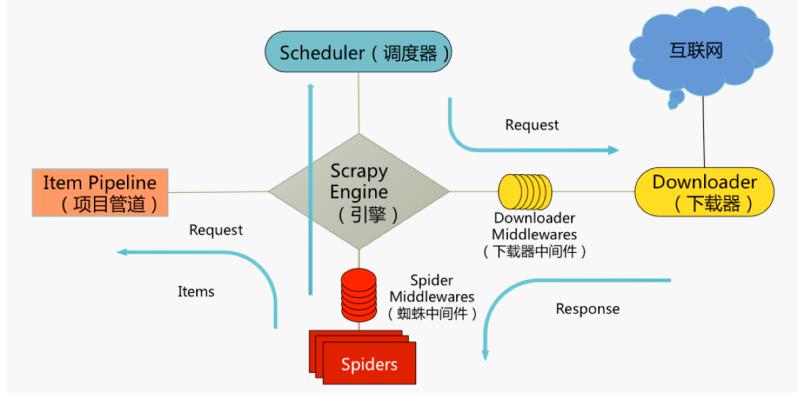
Scrapy 运行流程:
1.引擎向 spiders 要链接(url)
2.引擎将要爬取的链接(url)给调度器
3.调度器将链接(url)生成请求对象(Request)放入到指定的队列中
4.引擎从队列中取出一个请求(Request)交给下载器处理
5.下载器发送请求(Request)获取互联网数据
6.下载器将数据(Response)返回给引擎
7.引擎将数据(Response)交给spiders
8.spiders 通过 xpath 等解析该数据(Response)得到实体(Item)或链接(url)
9.spiders 将解析后实体(Item)或链接(url)回给引擎
10.引擎判断数据(如果是实体(Item)交给管道处理,如果是链接(url)交给调度器
Scrapy 使用流程:
scrapy startproject <project_name>
cd <project_name>
scrapy genspider <spider_name> <domain>
scrapy crawl <spider_name>
爬虫的编写: 当运行了上面命令 scrapy genspider后,会在目录 -> -> 下生成 , 这就是需要编写的爬虫文件,命令已经用模板生成了它的默认代码,假如命令为:scrapy genspider my_spider scrapyd.cn,则生成的代码如下:
import scrapy
class MySpiderSpider(scrapy.Spider):
name = 'my_spider'
allowed_domains = ['scrapyd.cn']
start_urls = ['http://scrapyd.cn/']
def parse(self, response):
pass